728x90
목차
더보기
01 _ 하둡 구성요소
01 _ 01 _ Hadoop Common
01 _ 02 _ Hadoop HDFS (Hadoop Distributed File System)
01 _ 03 _ Hadoop YARN (Yet Another Resource Negotiator)
01 _ 04 _ Hadoop Mapreduce
01 _ 05 _ Hadoop Ozone / Apache Ozone
02 _ 하둡 버전별 특징
02 _ 01 _ OverView
02 _ 02 _ 하둡 v1
02 _ 03 _ 하둡 v2
02 _ 04 _ 하둡 v3
01 _ 하둡 구성요소
01 _ 01 _ Hadoop Common
- 하둡의 다른 모듈을 지원하기 위해 일반적으로 사용되는 유틸리티 및 라이브러리 (공통 컴포넌트 모듈)
- 작업 지원 및 모니터링을 위한 기능 제공
- 하둡 공식 깃헙( https://github.com/apache/hadoop-common )에서 모듈들 확인 가능
01 _ 02 _ Hadoop HDFS (Hadoop Distributed File System)
- 하둡 분산형 파일 시스템
- 분산 저장을 처리하기 위한 모듈
- 여러개의 서버를 하나의 서버처럼 묶어서 데이터를 저장
하둡 VS HDFS
하둡은 데이터를 저장, 처리 및 분석할 수 있는 오픈 소스 프레임워크
HDFS는 데이터에 대한 액세스를 제공하는 하둡의 파일 시스템
즉 HDFS는 하둡의 모듈
01 _ 03 _ Hadoop YARN (Yet Another Resource Negotiator)
- 하둡의 리소스 관리 구성 요소
- 병렬처리를 위한 클러스터 자원관리 및 스케줄링 담당
- 배치, 스트림, 상호작용 및 그래프 처리를 위해 데이터를 처리 및 실행하며, 모든 데이터는 HDFS에 저장
01 _ 04 _ Hadoop Mapreduce
- 상용 하드웨어의 대규모 클러스터(수천 개의 노드)에서 데이터를 병렬로 처리할 수 있게 해주는 소프트웨어 프레임워크
- 맵리듀스의 작업 방식은 일반적으로 다음과 같다.
- input data-set을 병렬처리가 가능하도록 독립적인 chunk로 분할
- map 의 결과물을 정렬함으로써, input의 task 수행 비용 감소
- input과 output 은 일반적으로 파일 시스템에 저장
01 _ 05 _ Hadoop Ozone / Apache Ozone
- 하둡을 위한 확장성있는 분산 객체 저장소
- 기존 HDFS의 단점을 보완하고, 클라우드 네이티브, 컴퓨팅과 스토리지간 분리된 환경을 지원하는 차세대 HDFS 기술
- 공식 깃헙 ( https://github.com/apache/ozone ) 에서 목적성을 확인할 수 있음.
02 _ 하둡 버전별 특징
02 _ 01 _ OverView
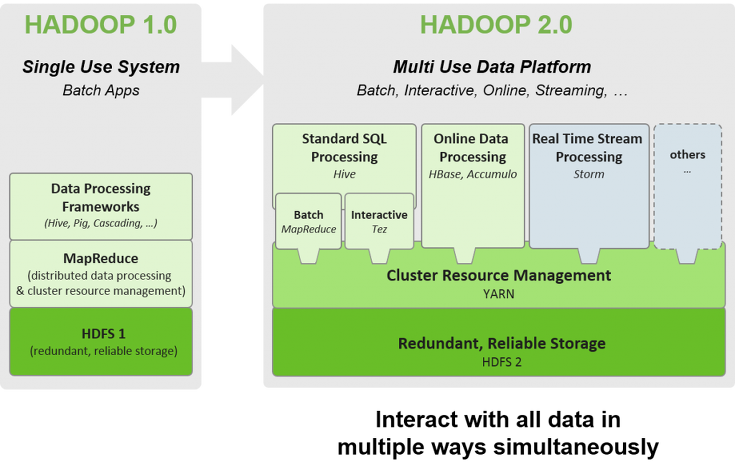
하둡 v1
- 병렬처리(맵리듀스) → 잡 트래커 + 태스크 트래커가 담당
- 분산저장(HDFS) → 네임노드 + 데이터노드가 담당
- 하지만, 병렬처리의 클러스터의 자원관리와 애플리케이션의 라이프사이클 관리를 잡트래커가 모두 담당하여 병목현상 발생
- ⇒ 이 문제를 v2 에서 해결
하둡 v2
- 잡트래커의 병목현상을 개선하기 위해 YARN 아키텍처 도입
- 잡트래커의 기능을 분리하여
- 클러스터 자원관리 → 리소스 매니저, 노드 매니저
- 애플리케이션 라이프 사이클 관리 → 애플리케이션 마스터 + 컨테이너
하둡 v3
- 이레이져 코딩 도입 → HDFS 데이터 저장 효율성 증가
- YARN 타임라인 서비스 개선, 쉡스크립트 재작성 안정성 높임.
- 맵리듀스 처리에 네이티브 프로그램 도입 → 성능 개선
02 _ 02 _ 하둡 v1


분산저장 (HDFS)
- 네임노드 (NameNode)
- 블록 정보를 가지고 있는 메타데이터 관리
- 데이터 노드 관리
- 데이터노드 (DataNode)
- 데이터를 블록 단위로 나누어서 저장
- 블록단위 데이터는 복제하여 유실에 대비
병렬처리 (맵리듀스)
- 잡트래커 (JobTracker)
- 전체 작업의 진행상황 관리
- 자원 관리 처리
- 클러스터당 최대 4000대의 노드를 등록할 있음.
- 태스크트래커 (TaskTracker)
- 실제 작업 처리
- 병렬 처리의 작업 단위는 슬롯 (slot)
- 맵 슬롯
- 입력 데이터를 읽고, 지정된 맵 함수를 적용하여 중간 결과를 생성하는 역할
- 리듀스 슬롯
- 맵 태스크에서 생성된 중간 결과를 가져와서 최종 결과를 생성하는 역할
한계점
- 클러스터가 100% 활용되지 않을 수 있다.
- 실행 시점에 역할이 정해지면 슬롯의 용도를 변경할 수 없기 때문에 맵 작업이 진행 중에는 리듀스 슬롯은 대기 상태
02 _ 03 _ 하둡 v2
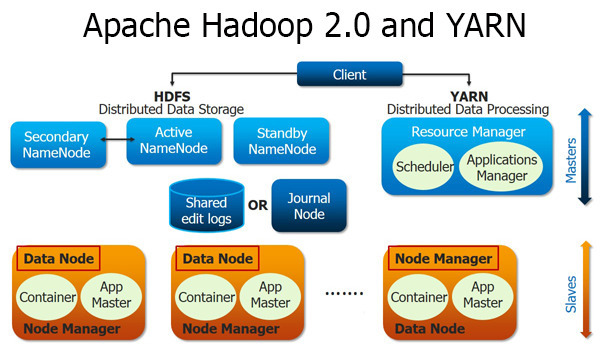
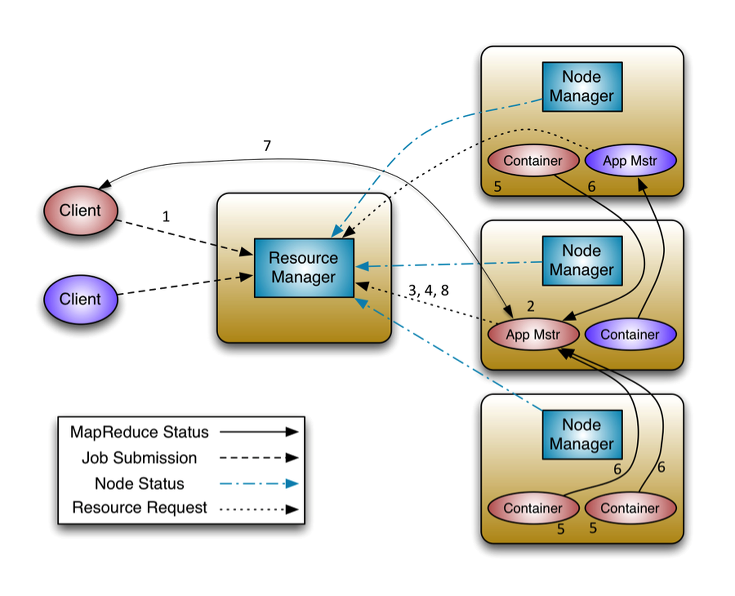
YARN 아키텍처
- 잡트래커의 기능 분리
- 자원 관리 → 리소스 매니저 + 노드 매니저
- 애플리케이션의 라이프 사이클 관리 → 애플리케이션 마스터가 담당
- 작업의 처리 → 컨테이너가 담당
- 자원 관리와 애플리케이션 관리의 분리를 통해 클러스터당 1만개 이상의 노드 등록 가능
YARN 아키텍처의 작업
- 작업의 처리 단위는 컨테이너
- 작업이 제출되면 → 애플리케이션 마스터가 생성됨
- 애플리케이션 마스터가 → 리소스 매니저에 자원을 요청
- 실제 작업을 담당하는 컨테이너를 할당 받아 작업을 처리
- 작업이 종료되면 클러스터를 효율적으로 사용할 수 있음.
YARN 아키텍처에서 MR 대신
- MR로 구현된 작업이 아니어도 컨테이너를 할당 받아서 동작할 수 있기 때문에
- Spark, HBase, Storm 등 다양한 컴포넌트들을 실행할 수 있다.
02 _ 04 _ 하둡 v3

이레이져 코딩으로 → 저장소 효율성
- 기존
- 하둡 v2까지 HDFS에서 장애 복구를 위해 파일 복제를 이용
- 기본 복제가 3개이므로, 파일 1개당 2개의 복제본을 가짐.
- 이로 인해 1G 데이터 저장에 3G의 저장소를 사용
- v3에서는
- 이레이져 코딩은 패리티 블록을 이용하여
- 1G 데이터 저장에 1.5G의 디스크를 사용하게 되어
- 저장소의 효율성이 증가 → HDFS 사용량 감소
YARN 타임라인 서버 개선
- 하둡 v1부터 사용하던 쉘스크립트를 다시 작성하여 버그를 해결
- 스크립트 재작성및 이해하기 쉬운 형태로 수정
- JAVA8 지원
- 네이티브 코드 최적화
- 고가용성을 위해 2개 이상의 네임노드 지원
- 하나만 추가할 수 있었던 스탠바이 노드를 여러개 지원가능 스탠바이 노드
- Ozone 추가
- 오브젝트 저장소 추가
기본 포트 변경
- NameNode
- 50470 → 9871
- 50070 → 9870
- 8020 → 9820
- Secondary NameNode
- 50091 → 9869
- 50090 → 9868
- DataNode ports
- 50020 → 9867
- 50010 → 9866
- 50475 → 9865
- 50075 → 9864
레퍼런스
- https://wikidocs.net/26170
- https://hadoop.apache.org/docs/r3.1.1/index.html
- https://duetys.tistory.com/entry/hadoop-10-vs-20
- https://www.databricks.com/kr/glossary/hadoop-distributed-file-system-hdfs
앞으로 하둡 구성요소 5가지에 대해 공부하며,
학습한 내용 및 실습 과정을 포스팅하려고 합니다 🫠