들어가며
포스팅된 글은 아래에 첨부된 논문과 유튜브 영상을 바탕으로 공부를 한 내용입니다.
이외에도 구글링을 통해 다양한 글들을 참고하며 공부한 내용을 포스팅 한 것 입니다.
논문 제목: Image Style Transfer Using Convolutional Neural Networks (CVPR 2016)
논문 링크: https://rn-unison.github.io/articulos/style_transfer.pdf
유튜브 설명

유튜브 영상에서 CNN 모델에 대해서 설명해줬는데
Channel 의 수와 그 크기는 서로 반비례 관계라고 한다.
Channel 의 수가 많아지면 많아질수록 Channel 의 너비와 높이는 줄어든다고 한다.
사실 여기서 말하는 Channel도 모르겠고, Filter 도 뭐를 지칭하는 말인지 모르겠다.
Feature 는 대략 짐작은 가지만 정확히 아는 것도 아닌 것 같다.
이런 기본 적인 것들을 알아야 Feature Map 을 이해할 수 있을 것 같다.
CNN (Convolutional Neural Network) 구조
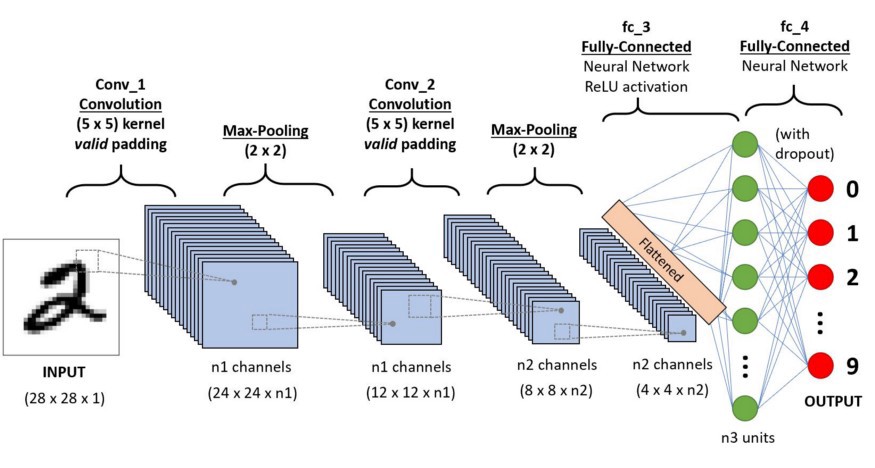
위에 있는 사진은 CNN (Convolutional Neural Network) 의 구조를 나타낸 예시이다.
INPUT 이미지에서 특징을 추출해서 반복적으로 세분화하는 방식이라고 이해하면 될 것 같다.
CNN (Convolutional Neural Network) 은 기본적으로 다음과 같은 단계를 가진다고 한다.
① Fisrt Convolutional Layer
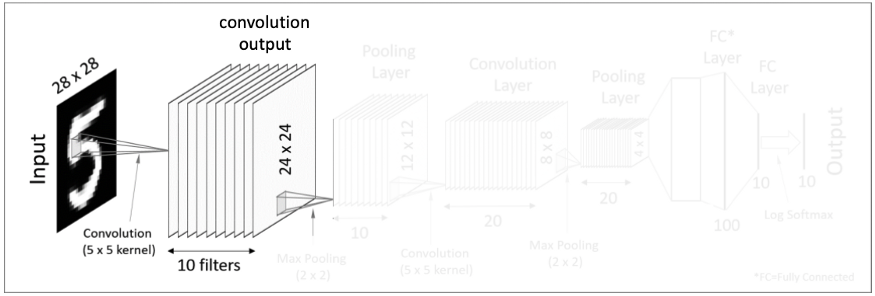
Fisrt Convolutional Layer 단계는 Input 이미지에 Convolution을 하여
Convolution output인 결과값 feature mapping을 얻어낸다.
위에 있는 이미지로 설명하면, 우선 Input 이미지는 크기가 28X28 인 상태이다.
Input 이미지에 10개의 5X5 kernel 을 사용하여 10개의 24X24 matrics를 결과값으로 만들어낸다.
즉 한 이미지의 특징을 추출한 부분을 10개로 세분화 시켰다고 이해하면 된다.
그와 동시에, 크기는 28X28 에서 24X24 로 줄어들었다고 생각하면 된다.
② First Pooling Layer

First Pooling Layer 단계는 convolution ouput 의 크기(dimension)를 줄이는 과정이다.
위에 이미지로 설명을 하면, convolution ouput 은 24X24 matrics인 상태이다.
이때 Pooling 을 하면서 24X24 를 12X12 matrics로 축소시켜주는 것이다.
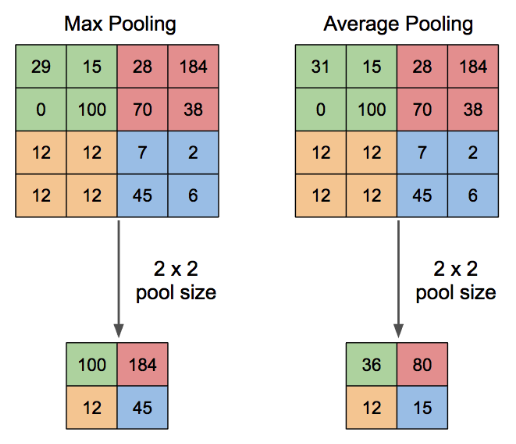
Pooling 할때는 대표적으로 2가지 방법을 사용하는데,
하나는 Max Pooling 이고, 다른 하나는 Average Pooling 이다.
Max Pooling 은 이전의 matrics에서 가장 큰 값을 대표값으로 가져오는 것이고
Average Pooling 은 이전의 matrics에서 평균값을 대표값으로 가져오는 것이다.
그래서 결론은 First Pooling Layer 단계를 통해,
convolution ouput 의 크기(dimension)는 감소했지만 그 filter의 수 는 변화가 없다.
③ Second Convolutional Layer

Second Convolutional Layer 단계를 통해, 또 다시 convolution output을 얻어낸다.
이때 First Convolutional Layer 단계와 동일하게 pooling output의 개수는 늘리면서 그 크기를 줄인다.
위의 이미지를 보면 filter의 수는 10개에서 20개로 늘어났고, 크기도 12X12 에서 8X8로 줄어들었다.
④ Second Pooling Layer
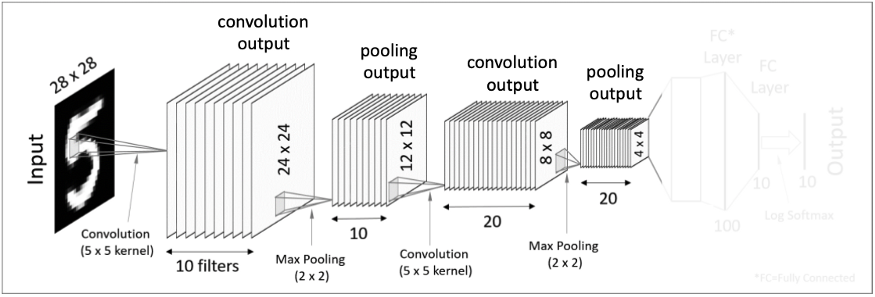
Second Pooling Layer 단계는 First Pooling Layer 와 동일하다.
convolution output의 filter 수는 그대로 유지하면서, 그 크기만 감소시킨다.
그래서 위의 이미지를 보면 filter의 개수는 20개로 동일하지만
크기가 8X8 에서 4X4로 줄어들었다.
⑤ Flatten (Vectorization)

Flatten (Vectorization) 는 pooling output을 벡터화 해주는 단계이다.
4X4X20 인 pooling output 을 각각 세로줄을 일렬로 세워서 벡터(vector) 형태로 만들어준다.
그럼 이때 벡터는 320-dimension을 가지게 된다.
⑥ Fully-Connected Layers (Dense Layers)

이제 Fully-Connected Layer (Dense Layer) 를 적용시키고
마지막으로 Softmax activation function을 적용시켜주면 최종 결과물이 출력된다.
사실 이부분은 아직도 이해가 안가서 나중에 다시 공부하고 수정할 생각
합성곱 (Convolution)

합성곱(Convolution)은 행렬(matrix)과 행렬(matrix) 간의 내적 (Inner Product) 을 계산해주는 것이다.
위의 이미지와 같이 A 행렬과 B 행렬을 내적해주는 것이 합성곱의 예시이다.


위의 사진처럼 Input Image의 matrix 와 Filter(Kernel) 의 matrix를 내적해주는 것이 convolution이다.
이때 Input Image의 크기보다 작은 Filter(Kernel)을 사용해주면서 convolution output의 크기도 줄어든 것을 볼 수 있다.
필터 (Filter)
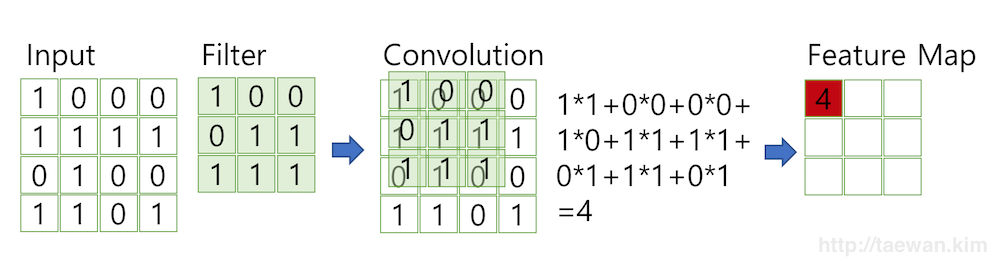
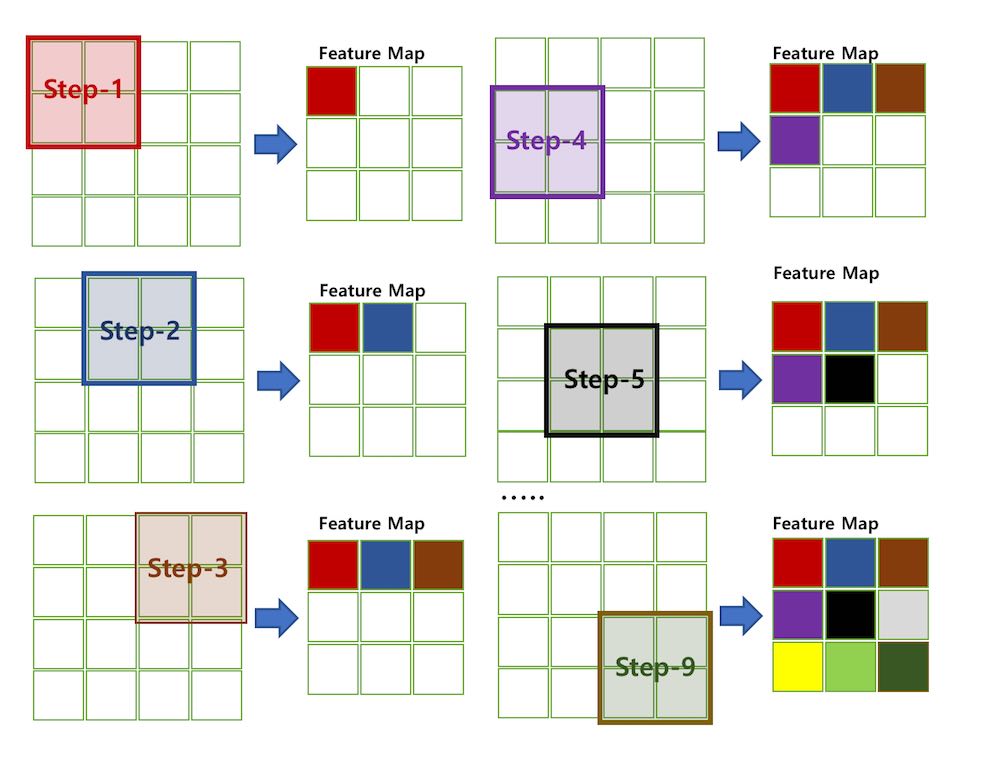
위에서 언급했듯이 Input 을 통해 Feature Map을 얻어내기 위해서
Convolution 과정을 거쳐야 하는데
이때 Input과 Convolution 될 아이템이 Filter 이다.
참고로 Filter는 Kernel로 불리기도 한다.
Filter는 이미지의 특징을 찾아내는 것이 목적이며, CNN에서 학습의 대상이 Filter인 것이다.
채널 (Channel)

보통 우리가 알고있는 color 이미지는 RGB 3개로 표현된 3차원 데이터이다.
즉 color 이미지는 red channel, blue channel, green channel 로 이루어져있다.
추가로 흑백 이미지의 경우 하나의 channel로 이루어져있다.

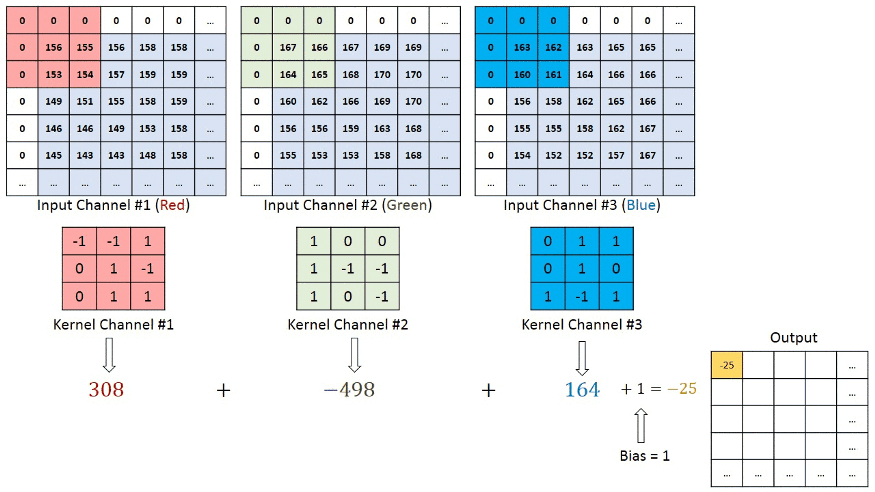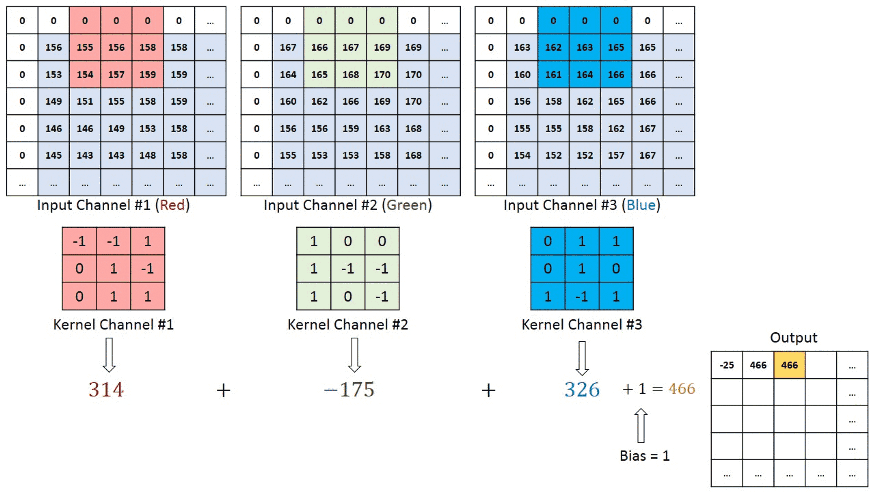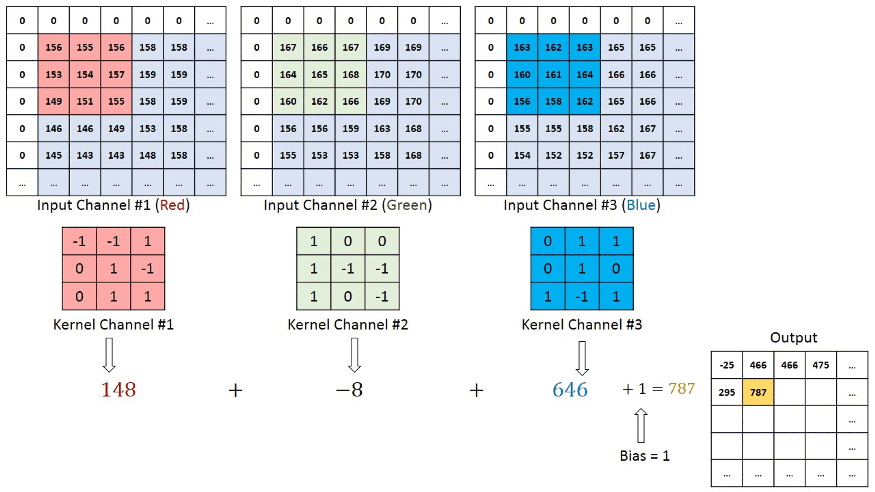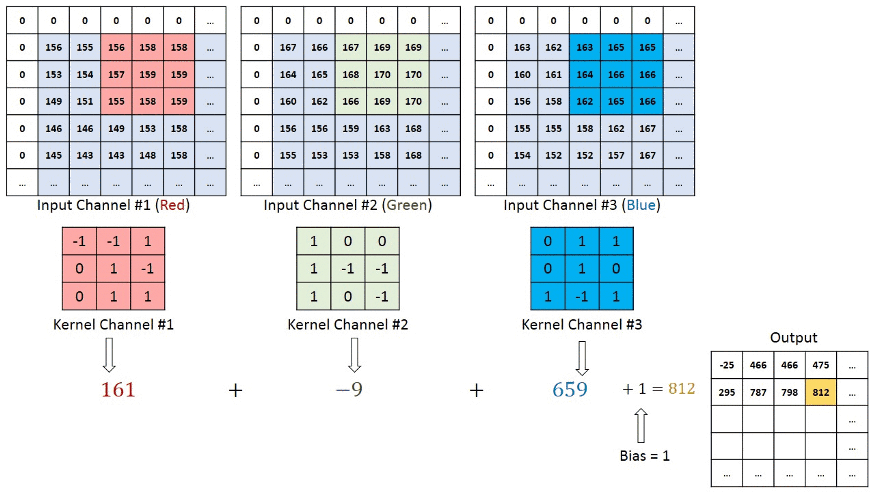
그래서 하나의 Input 이미지를 3개의 channel로 분리시켜서 convolution을 진행한다.
이때 3개의 channel은 위에서 언급했던 red channel, blue channel, green channel 이다.
특징 맵 (Feature Map)

특징 맵 (Feature Map) 은 결국 convolution의 최종 결과물이다.
위에서 계속 반복해서 얘기했던 과정들의 결론이라는 얘기다.
요약하면 Input 을 3개의 channel로 분리시킨 후,
각각 filter와 convolution 시킨 결과들을 합한 것이 Feature Map이다.
그래서 결론
CNN 모델은 당연히 Convolutional Layer 와 Pooling Layer 의 과정을 반복적으로 진행하니까
레이어가 깊어질수록 channel 의 수가 많아지고 너비와 높이가 줄어드는 것이다.
그리고 특징을 잘 추출하기 위해서 각각 다른 filter를 이용하는 것도 당연한 얘기다.
이제야 유튜브에서 설명한 내용이 이해가 갔다.
마치며
평소에 CNN 얘기 자주 듣긴 했는데 뭔지 모르고 있다가 이번 기회에 공부하니까 재밌긴하다
새벽 2시 다되가는데 잘까 공부 더할까 고민되네
다음주면 슬슬 시험 준비해야되는데 프로젝트 준비하는 게 더 재밌어서
이것만 계속 파고 싶다
학점 잘가 👋



